
Consonants
The Consonants analysis consists of a series of algorithms to determine the accuracy of consonants in singleton and complex syllable onsets and codas as well as in heterosyllabic clusters. Options also include the selection of OEHSs (onsets of empty-headed syllables) as well as syllable appendices, which serve to identify particular syllabification patterns in languages like French or Dutch (among others).
Parameters
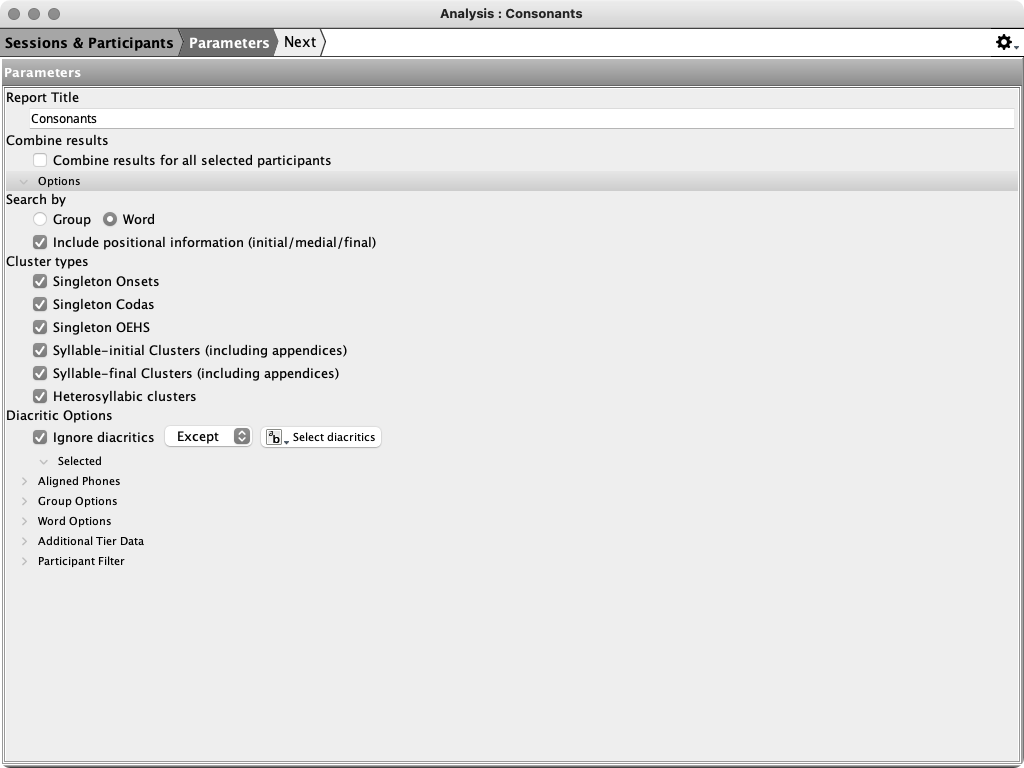
For each participant, and for each context selected in the options illustrated in Figure X, Phon provides a series of reports, as follows (example uses selection as show above):
Consonants across all positions
Global Accuracy: List and frequency counts of all of the consonants, each identified by syllable position (e.g. O2 = second position of syllable onset) and marked for their behaviours as Accurate, or undergoing Substitutions, Deletions, or Epenthesis. Sums and percentages are reported for each behaviour.
Figure 2. Consonants across all positions 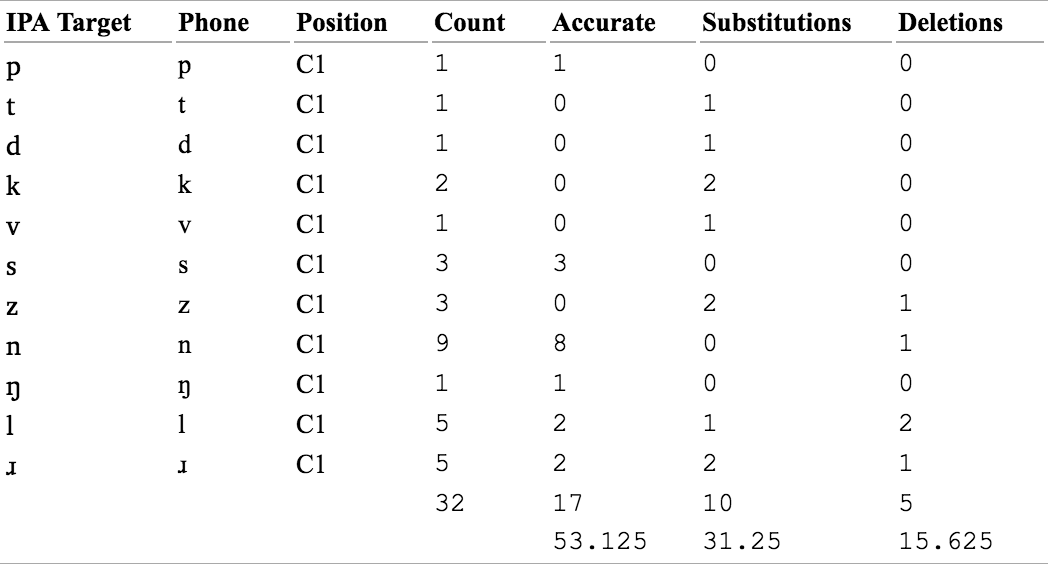
Syllable-initial Accuracy: as per above, for syllable-initial consonants and clusters.
Syllable-final Accuracy: as per above, for syllable-initial consonants and clusters.
Consonants in singleton onsets and codas
Singletons Accuracy: List and frequency counts of all of the consonants in singleton onsets and codas, each identified by syllable position (e.g. O1 = syllable onset) and marked for their behaviours as Accurate, or undergoing Substitutions, Deletions, or Epenthesis. Sums and percentages are reported for each behaviour.
Syllable-initial Accuracy: as per above, for syllable-initial consonants and clusters.
Syllable-final Accuracy: as per above, for syllable-initial consonants and clusters.
Accuracy report for each consonant type, by syllable position, alongside descriptive behaviours, sums and percentage:

Listing of each token in context, including corpus/session, the word containing the consonant (in Orthography, IPA Target, IPA Actual) and the context within which the token was found. Within the Phon report preview, the user can click on each individual result to visualize it within its corresponding data record. Listings will also include columns for accurarcy ('Count', 'Accurate', 'Substitutions', 'Deletions', 'Epenthesis'.)
If 'Include positional information' is selected (default 'true') then listings will also include columns for position within the query domain.

Consonant clusters
The reports for consonant clusters are formatted as above, where the behaviour of each consonant is listed individually. Additional consonants or vowels produced which break up target clusters (e.g. blue produced as /bilu/) are also reported, with the “+” diacritic to indicate their status as epenthetic.
Other parameters
Report Outline
A sample table of contents is displayed below. Bold level elements are section headers while italic items are tables.
-
Consonants
-
Parameters
-
Participant 1
-
Global Accuracy
-
Syllable-initial Accuracy
Syllable-final Accuracy
- Singletons
- Singleton Accuracy
- Syllable-initial Accuracy
- Syllable-final Accuracy
- /c1/
- Listing
- /c2/
- Listing
- … (for each singleton consonant)
- Clusters
- Cluster Accuracy
- Syllable-initial Accuracy
- Syllable-final Accuracy
- /c1/
- Listing
- /c2/
- Listing
- … (for each consonant cluster)
-
- … (for each selected participant)
- Listing (all participants)
-
Example
Click the link below to view an example report.
 Example Report
Example Report